Overfitting and Underfitting are two fundamental problems due to which a machine learning model performs poorly. Any machine learning model's primary objective is to generalize effectively. Here, generalization refers to the ability of an ML model to adapt the provided set of unknown inputs to produce an acceptable output. It indicates that it can generate trustworthy and accurate output after undergoing training on the dataset.
Before we move on to overfitting and underfitting, we need to be familiar with some prerequisite terms:
- Noise: Noise stands for unnecessary or irrelevant data, or other similar outliers, that do not follow the general trend of the overall dataset.
- Bias: Bias is the error rate of the training data, and occurs due to the oversimplification of machine learning algorithms when the model makes assumptions to make a function easier to learn.
- Variance: Variance is defined as the difference in the model's error rate with the training data and the model's error rate with the testing data. We need a low variance for our model to be generalized well.
Overfitting
Overfitting occurs when our model tries to cover all the data points in the training data set, so much so that it takes into account a large amount of noise as well. As a result, the model performs well with the training data, but falls short when it comes to the testing data. Hence, it has a low bias but a high variance.
Overfitting occurs when the model tries to capture too many details, that is, the chances of overfitting occurring increase as we provide higher amounts of training to the model with a limited dataset.
We can avoid/reduce overfitting by the following measures:
- Reducing the complexity of the model
- Increasing the amount of training data
- Using K-fold cross-validation (a method for determining how well the model performs on fresh data)
- Using Regularization techniques such as Lasso and Ridge
- Stopping early during the training phase (by keeping an eye on the loss and halting training as it begins to increase)
- Removing some features
Underfitting
Underfitting occurs when our model is unable to discern the underlying pattern in the training data given. When the training is stopped at an early stage, the model fails to learn enough from the dataset, and hence its accuracy is reduced and it generates unreliable predictions. An underfitted model performs poorly on both training and testing data. Therefore, it has a high bias but a low variance.
When we have very little data to work with, the model tries to apply the rules of machine learning to such minimal data, and ends up with errors.
We can avoid/reduce underfitting by the following measures:
- Increasing the complexity of the model
- Increasing the amount of training data
- Removing as much noise as possible from the data
- Increasing the number of features, performing feature engineering
- Increasing the time duration of the training phase, increasing the number of epochs
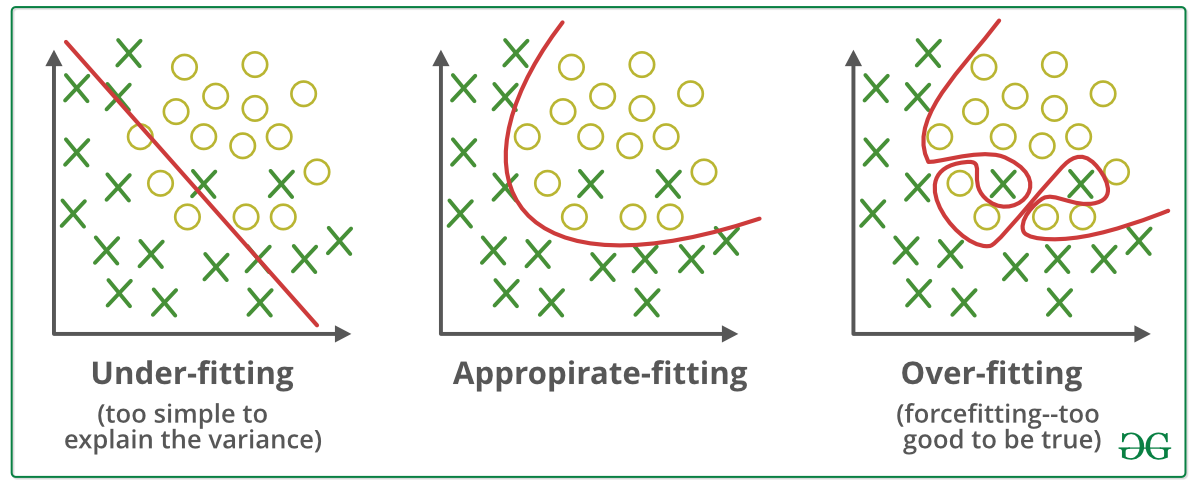
A graphical example of Underfitting, Overfitting, and “Good Fit”
Picture courtesy: GeeksForGeeks
Comments
Post a Comment